Evaluating and improving LLM confidence calibration in educational dialogue coding.
University of Florida · Florida State University · VIABLE Lab
Hongming (Chip) LiDr. Huan KuangDr. Anthony F. Botelho
When a model says “confidence: 0.9,” can we believe it?
Who we are
A quick hello from our team.
Hongming (Chip) LiPhD Candidate · University of FloridaDr. Huan KuangAssistant Professor · Florida State UniversityDr. Anthony F. BotelhoAssistant Professor · University of Florida
A collaboration across UF’s VIABLE Lab and Florida State University, working on AI in education, learning analytics, and educational data mining.
The problem
We want to trust high-confidence codes and review the rest.
An appealing workflow for LLM-assisted coding is a kind of triage. We’d accept what the model is confident about and flag what it isn’t for a human to check. That only helps if confidence tracks correctness, so the promise rests on one assumption that is worth testing.
Traditional MLCalibrated probabilities
A softmax over a trained objective. We have decades of theory and tools for trusting, and for fixing, these numbers.
vs
LLMsA number, written as text
The model writes “0.9” the same way it writes any token, without direct access to its own internal certainty. Is it a useful signal, or just plausible-looking text? That is our question.
The stakes · why this is urgent for our field
The question is sharpest for open-weight models.
FERPA
Student data often cannot leave institutional control, so a local, open-weight model is frequently the compliant option.
Budget
API costs can grow steep at scale for the large corpora educational research tends to produce.
Reproducibility
Open weights support transparent, replicable methods, a standard the field increasingly values.
So we ask not only whether commercial models are calibrated, but also whether the models researchers are often constrained to use can be trusted, and whether we can help.
The concepts · two questions, not one
“Calibrated” means more than “accurate.”
ECE
Is it overconfident?
Expected Calibration Error is the average gap between stated confidence and actual accuracy. A model that says 0.9 but is right about 0.45 of the time has a large ECE.
Naeini et al., 2015AUC
Can it rank correctness?
Does higher confidence mean more likely correct? 0.5 is random and roughly 0.7 and up is useful for decisions. This is what triage really needs.
Hendrycks & Gimpel, 2016ρ
Does the ordering hold?
Spearman’s ρ is the rank correlation between confidence and correctness, a second read on discrimination.
Guo et al., 2017
One distinction to keep in mind. A model can be quite overconfident (high ECE) and still rank its answers reasonably (decent AUC). For triage, the ranking is what matters most.
Three questions that build on each other
Diagnose, explain, then intervene.
RQ1
How well-calibrated is LLM confidence across models in educational coding?
RQ2
What mechanism governs confidence, and can demonstration examples reshape it?
RQ3
Can activation-level intervention improve calibration in open-weight models?
Each study answers one question and motivates the next. Study 1 characterizes the problem, Study 2 explains why the obvious fix falls short, and Study 3 explores an alternative that helps.
Method · the dataset
633 student–AI dialogues, expert-coded into nine categories.
633
Real student prompts
Messages students sent to ChatGPT for help in a graduate intro computer science course. Authentic, messy, in-the-wild data.
9
Mutually exclusive codes
collaboration, exploration, investigation, resource, framing, value judgment, default, example, and NA. A scheme refined over a prior study.
2
Expert human coders
Independent coding by trained qualitative researchers. Inter-rater reliability ran from Cohen’s κ of 0.65 to 0.94, substantial to strong.
One prompt, three models, the way practitioners do it.
Every model gets the same prompt. It predicts a category, reports a confidence from 0 to 1, and gives a brief rationale. We use greedy decoding (temperature 0) so runs are reproducible.
gpt-5-minigemini-3-flashllama-3.1-8b
We study verbalized confidence, the number the model writes, rather than token logits. It is the common paradigm in applied workflows, and it is the one signal we can compare fairly across closed APIs and open weights.
Study 1 · RQ1 · the diagnosis
All three models were consistently overconfident.
0.89–0.92
Mean stated confidence, nearly identical across all three models.
0.34–0.52
Actual accuracy on a hard nine-way task (chance is about 0.11).
The gap
A confidence–accuracy gap of 0.40 to 0.55, and ECE points the same way across every model we tested.
In our data, overconfidence showed up across all three models rather than in just one. A practical reading is that the raw number is best not taken as a probability.
Study 1 · the more useful result
Ranking varied, and accuracy did not predict it.
On AUC, the ability to rank correct above incorrect, the two closed models land in a range that is usable for triage. The open-weight model sits much closer to chance.
One twist gemini was the most accurate model (0.52) yet ranked its own correctness a little worse (AUC 0.67) than gpt-5-mini (0.44 accuracy, 0.69 AUC).
gpt-5-mini · AUC 0.69Moderate, enough to help prioritize review.gemini-3-flash · AUC 0.67Moderate, despite the highest accuracy.llama-3.1-8b · AUC 0.57Close to chance, so triage offers limited value.
Knowing the answer and knowing when you know it look like different abilities here, so it helps to evaluate calibration on its own rather than infer it from accuracy.
Study 1 · where the errors live
Predictions lean toward a few “easy” categories.
example and collaboration recognized well; finer codes confused.most accurate, but still leans on a few categories.sparsest diagonal, the weakest agreement with experts.
Rows are the human code, columns the model’s. Concrete codes like example and collaboration are recognized well; subtler intent codes like investigation and framing are where the models tend to slip.
Study 2 · RQ2 · the obvious fix
Can we just show the model a lower confidence?
A natural prompt-engineering move is to change the example value in the output-format spec and see if the model follows. We ran three conditions on the open-weight model, the one with the most room to improve.
·
Baseline
Format shows confidence: [number from 0 to 1], with no value demonstrated.
↑
High anchor
Format shows confidence: 0.95. A plausibly-high value.
↓
Low anchor
Format shows confidence: 0.05. An implausibly-low value.
Anchoring bias is well documented in humans and in LLM number tasks. Our open question is whether it is symmetric, or filtered by what the model finds plausible.
Study 2 · the result
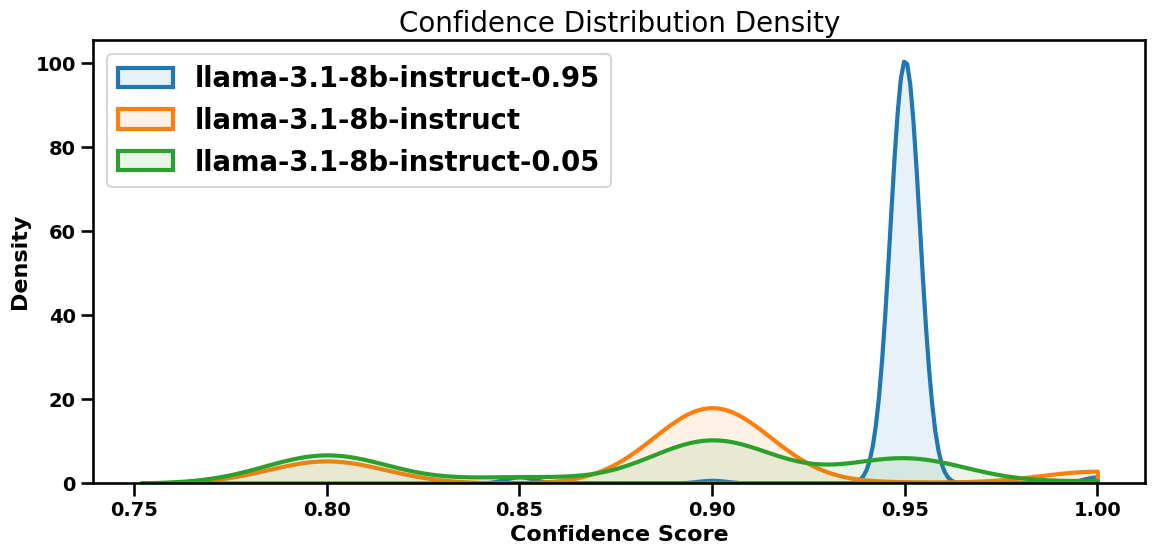
It follows high anchors and ignores low ones.
The asymmetry is striking in our data.
High anchor (0.95)96.5% of outputs land at exactly 0.95, a near mode collapse.
Low anchor (0.05)0% adoption. Outputs return to the default 0.80 to 0.95 range.
Blue: 0.95 anchor, a single sharp spike. Green: 0.05 anchor, no peak there at all. Orange: baseline.
Study 2 · the interpretation · a named mechanism
Plausibility-gated anchoring.
The model tends to adopt a shown value only when it falls inside a range it already treats as plausible for the task. Anchoring here is not symmetric, it appears gated by a learned prior. Supporting this, at baseline 99% of outputs sit on just three values (0.80, 0.90, 1.00), and the low anchor reshuffles among those same values rather than moving toward 0.05.
Inside the plausible band 0.95 → adopted, collapsesa learned prior gates what gets throughOutside it 0.05 → rejected entirely
Study 3 · RQ3 · going below the prompt
If prompting is gated, intervene on the activations.
01Record
Read the activations from one middle layer as the model runs all 633 samples (we tried layers 16 and 22).
02Group
Label each sample well-calibrated or poorly-calibrated, by whether confidence matched correctness.
03Find a direction
Take the average activation of each group, then subtract. The difference is one direction in the model that separates them.
04Nudge
Add a small multiple of that direction back while the model runs. No retraining, no weight changes.
05Test fairly
Build the direction on one half (316), then measure it on the other, held-out half (317).
This needs to read and edit internal states, which is only possible with open weights. The same constraint that makes calibration hard also makes this approach available.
Study 3 · the result
Small but consistent gains that hold out of sample.
Both settings nudged ranking in the right direction on the half of the data not used to build the direction. The effects are modest, and we report them as such.
Being clear the overconfidence gap stays large. This shifts the ordering of confidence a little, it does not turn the number into a probability.
AUC 0.565 → ~0.585About +0.02 in both settings we tried.Spearman ρ 0.13 → ~0.16A small absolute rise (large in relative terms, from a low base).Held outMeasured on data not used to build the direction, so it is not just fitting the training half.
A cautious read. Some calibration-relevant signal seems to live in the representations, and a light-touch nudge can surface a little of it without retraining. We see it as a complement to prompting, not a fix.
Synthesis · one coherent story
Verbalized confidence looks more like a learned prior than an uncertainty estimate.
Study 1 found overconfidence across all three models, with ranking ability that varies. Study 2 offered a reason, confidence concentrates on a few high values the model treats as plausible. Study 3 suggested some of that signal can be surfaced from inside the model. Three studies, one through-line.
Overconfident across modelsShaped by a priorPartly recoverable from within
What to take back to your workflow
Four rules for trusting LLM confidence.
Triage on AUC, not accuracy
Around AUC 0.68, routing low-confidence items to review can help. Near 0.56 it offers little, so check discrimination on your own data first.
from Study 1
Rankings, not probabilities
With ECE above 0.40, a “0.9” is not a 90% chance. Confidence is safer for ordering items than for setting an accept threshold.
from Study 1
Be careful demonstrating confidence
A shown value tended to either collapse the distribution or be ignored, so it is worth thinking twice before fixing confidences in few-shot examples.
from Study 2
Steering is worth a look
For local open-weight setups, activation steering is one option that gave small gains for us. Our code is open if you want to try it.
from Study 3
Scope & what comes next
What this study does not yet show.
One dataset, one schemeIntro CS prompts, nine categories. Other domains and granularities may behave differently.One open modelllama-3.1-8b. Larger models may shift where the plausibility range sits.Modest steering, in-datasetGains were small and tested within one dataset. We have not confirmed them across datasets.Single-turn, zero-shotMulti-turn or chain-of-thought elicitation could change the picture.
Where we want to go
Open, useful next steps.
Per-category calibration would say which codes are safe to automate and which still need a person. Beyond that, larger models, richer elicitation, and replication across datasets.
The honest frame we offer a diagnosis and one early intervention, not a solved problem. The aim is to help you judge when LLM confidence can be trusted.
Thank you
Questions?
A simple takeaway. Read the number as a ranking rather than a probability, and consider steering if you are on open weights. Happy to talk about the metrics, the anchoring mechanism, or the steering code.
Hongming (Chip) Li · hli3@ufl.eduHuan Kuang · hkuang2@fsu.eduAnthony F. Botelho · abotelho@coe.ufl.edu
Paper page · PDF · figures · open-source steering toolkit
 Hongming (Chip) LiPhD Candidate · University of Florida
Hongming (Chip) LiPhD Candidate · University of Florida Dr. Huan KuangAssistant Professor · Florida State University
Dr. Huan KuangAssistant Professor · Florida State University Dr. Anthony F. BotelhoAssistant Professor · University of Florida
Dr. Anthony F. BotelhoAssistant Professor · University of Florida



 Paper page · PDF · figures · open-source steering toolkit
Paper page · PDF · figures · open-source steering toolkit